A Modern & Sustainable Analytics Stack
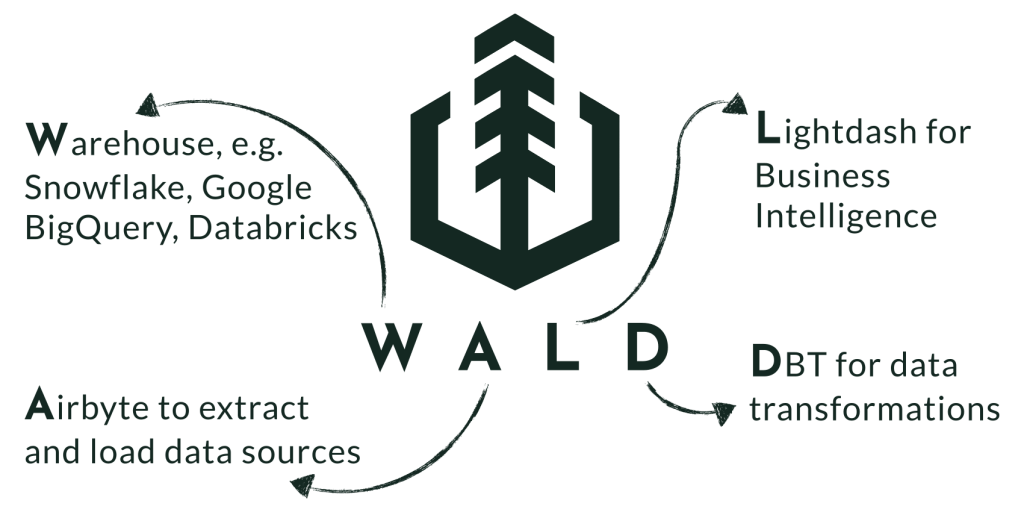
The WALD Stack is composed of four powerful technologies, i.e. a modern, cloud-computing Warehouse like Snowflake, Google BigQuery or Databricks Lakehouse, the open-source data integration engine Airbyte, the open-source full-stack BI platform Lightdash, and the open-source data transformation tool DBT.
The WALD Stack is sustainable as the three major components, i.e. Airbyte, dbt and Lightdash, are open-source and they are built and maintained by a community of developers, who are committed to its long-term success.

Airbyte is an open-source data integration platform that helps businesses move and consolidate data from different sources into a data warehouse or data lake. It offers pre-built connectors for over 200 data sources and destinations, including databases, cloud services, and APIs, which can be easily configured and customized through a user-friendly interface. Airbyte also allows for scheduling and monitoring of data pipelines, ensuring that data is reliably an efficiently transferred on a regular basis.
What sets Airbyte apart from other data integration solutions is its focus on being open source, modular, and extensible. This means that users have full control over their data pipelines and can easily add custom connectors, transformations, or destinations as needed. Additionally, Airbyte provides a hosted version of the platform, as well as a self-hosted option, making it accessible to businesses of all sizes and technical capabilities.

dbt (data build tool) is an open-source command-line tool that helps data analysts and engineers transform, test, and document data in their data warehouse. It allows for the creation of complex data transformation pipelines that can be easily maintained and version controlled using SQL code. dbt’s modular design allows users to build and test small, independent SQL scripts or models, which can be combined into larger workflows.
dbt’s key features include version control, automated testing, and documentation generation, making it easier to collaborate on data modeling and transformation projects. It integrates with various data warehouses, such as Snowflake, BigQuery, and Redshift, and can also connect to third-party tools for additional functionality.
Overall, dbt aims to improve the reliability and efficiency of data analytics by streamlining data transformation processes and promoting best practices for data modeling and documentation.

Lightdash is an open-source business intelligence (BI) tool that makes it easier for non-technical users to explore and visualize data from their data warehouse. It provides a user-friendly interface that allows users to create interactive dashboards, charts, and reports using SQL queries.
One of the key features of Lightdash is its ability to parse SQL queries and automatically generate visualizations based on the results. This makes it easy for non-technical users to explore data without having to write complex SQL queries or use a separate BI tool. Lightdash also provides a way for users to save and share their dashboards with others, making it easier to collaborate on data analysis projects.
Lightdash is designed to work with various data warehouses, including BigQuery, Snowflake, and Redshift, and can be easily installed and configured using Docker. Additionally, Lightdash’s code is open-source, which means users can customize it to suit their specific needs.
WALD Stack Architecture
The WALD Stack is an ELT-based software stack that uses Airbyte to extract data from a source and load it into a modern data warehouse like Snowflake, Google BigQuery, or Databricks Lakehouse. Data is transformed using dbt, which supports both SQL and Python transformations thanks to the Snowpark or Spark data frame API. The stack provides a unified and well-integrated approach to using a data frame API with dbt. Finally, Lightdash is used to analyse and visualize the data.
Read on to understand why the WALD Stack is based on a modern ELT approach instead of classical ETL.
Classical ETL
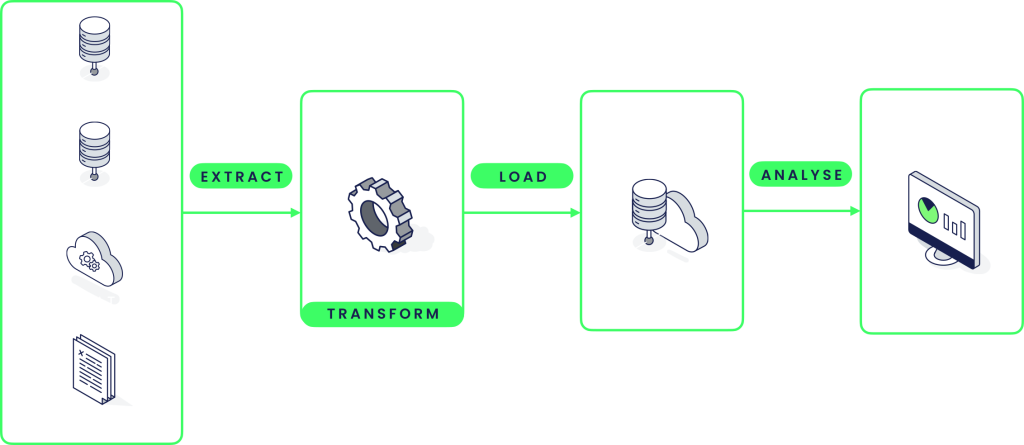
The classical ETL (Extract-Transform-Load) process involves extracting raw data from various sources, transforming it into a usable format, and loading it into a target destination like a data warehouse. To facilitate this process, a staging area like a data lake is often used to store the raw data before it undergoes transformation. However, using a different processing technology for the staging area can add extra complexity to the ETL process.
One downside of the ETL process is that it can be time-consuming and resource-intensive. The transformation step in particular can be complex and require significant computational resources. Additionally, managing and maintaining the ETL pipeline can be challenging, especially as the volume of data and number of data sources increases.
Overall, while the ETL process is a fundamental process in data warehousing, it is not without its challenges and downsides. The use of a staging area like a data lake can help mitigate some of these challenges but can also introduce additional complexity to the process.
Modern ELT
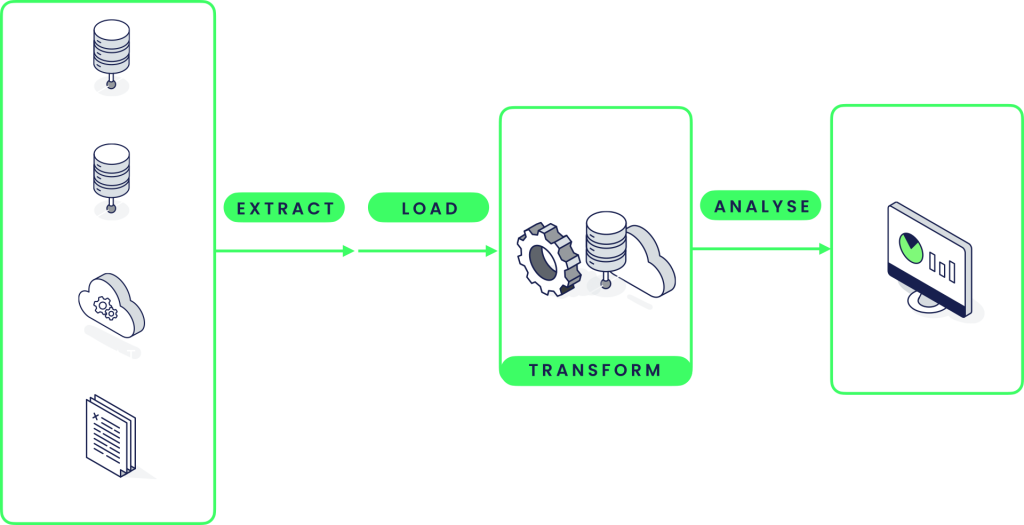
The ELT (Extract-Load-Transform) process is similar to the ETL process, but with the transformation step happening after the data has been loaded into a target destination like a data warehouse. This means that the raw data is first loaded into the target destination as-is, and then transformed using SQL or other processing tools directly within the target destination.
One major upside of the ELT process is that it can be faster and more efficient than the ETL process. This is because it minimizes data movement and reduces the need for complex data transformations outside of the target destination. Additionally, the ELT process can take advantage of the scalability and processing power of modern data warehouses, which are designed to handle large volumes of data and complex queries.
Another benefit of the ELT process is that it can make it easier to work with semi-structured and unstructured data. Since the data is loaded into the target destination as-is, without being transformed beforehand, it is easier to handle data in a variety of formats and structures. This can be especially useful for data sources like log files or social media feeds, which may not conform to a structured data model.
Overall, the ELT process can offer significant upsides over the traditional ETL process, including faster processing times, improved scalability, and better handling of semi-structured and unstructured data.
Try out the WALD Stack!

Want to see the WALD Stack in action? Check out our open-source demonstration project on GitHub! Using the Kaggle Formula 1 World Championship dataset and the data warehouse Snowflake, this project showcases how Airbyte, dbt, Lightdash, and a cloud-based data warehouse can work together seamlessly to transform and analyze data.
Visit our GitHub page to explore the WALD Stack and try it out for yourself!
Contact
Want to learn more about the WALD Stack or need help with implementation? We’re here to help! Email us at info@waldstack.org, and our team will be in touch shortly to answer any questions you may have and provide the support you need.
